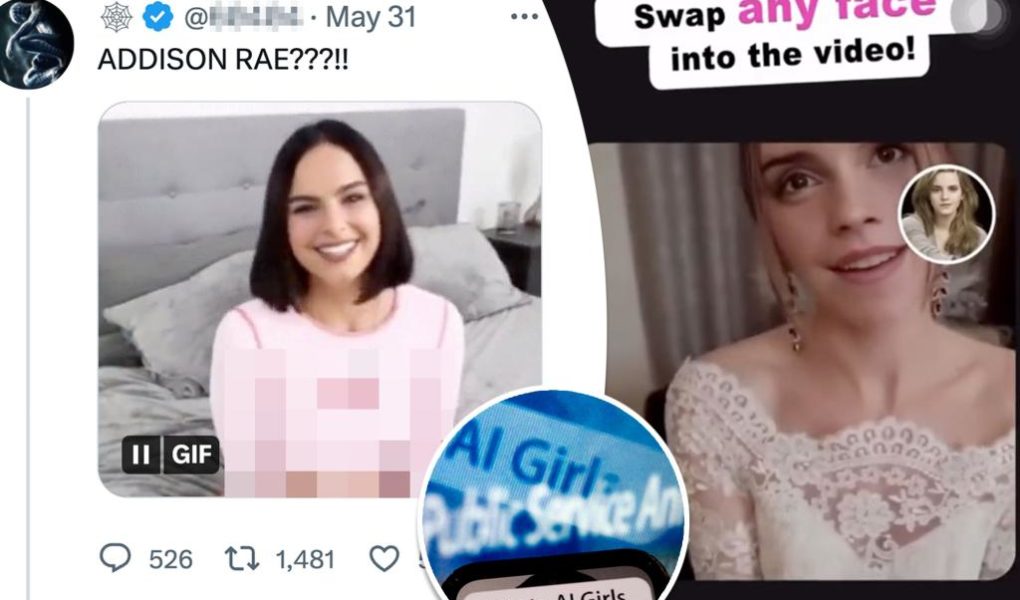
These deepfakes seem real to a startling number of people.
Humans are unable to detect over a quarter of deepfake speech samples made by artificial intelligence, according to new research from University College London.
In “deepfake” technology, “a person in an image or video is swapped with another person’s likeness,” according to the Massachusetts Institute of Technology. The technique has also been used to recreate people’s voices for scams.
The new UCL study, published last week in the journal PLOS One, used a text-to-speech algorithm trained on two publicly available datasets to create 50 deepfake speech samples in English and Mandarin.
The samples were played for 529 study participants who tried to decipher the real voices from the fake ones.

Participants were only able to identify fake speech 73% of the time, improving slightly only after they received training on how to recognize deepfake voices.
“Our findings confirm that humans are unable to reliably detect deepfake speech, whether or not they have received training to help them spot artificial content,” said Kimberly Mai, an author of the study and a PhD student in machine learning at UCL, said in a statement.
“It’s also worth noting that the samples that we used in this study were created with algorithms that are relatively old, which raises the question whether humans would be less able to detect deepfake speech created using the most sophisticated technology available now and in the future,” Mai continued.
The British study is said to be the first to explore humans’ ability to detect artificially generated speech in a language other than English.

English and Mandarin speakers showed similar detection rates, but English speakers often referenced breathing, while Mandarin speakers noted cadence when asked about their decoding methods.
The UCL researchers warn that deepfake technology is only getting stronger, as the latest pre-trained algorithms “can recreate a person’s voice using just a 3-second clip of them speaking.”
The scientists want to create stronger automated speech detectors to better be able to counter potential threats.
“With generative artificial intelligence technology getting more sophisticated and many of these tools openly available, we’re on the verge of seeing numerous benefits as well as risks,” said UCL professor Lewis Griffin, senior author of the study.
“It would be prudent for governments and organizations to develop strategies to deal with abuse of these tools, certainly, but we should also recognize the positive possibilities that are on the horizon.”

According to some experts, deepfakes are poised to play a dangerous role in the 2024 elections.
In March, video-sharing platform TikTok banned deepfakes of young people.
The move comes amid the proliferation of scams that use deepfakes to scare people into handing over money or pornographic images of themselves.
𝗖𝗿𝗲𝗱𝗶𝘁𝘀, 𝗖𝗼𝗽𝘆𝗿𝗶𝗴𝗵𝘁 & 𝗖𝗼𝘂𝗿𝘁𝗲𝘀𝘆: nypost.com
𝗙𝗼𝗿 𝗮𝗻𝘆 𝗰𝗼𝗺𝗽𝗹𝗮𝗶𝗻𝘁𝘀 𝗿𝗲𝗴𝗮𝗿𝗱𝗶𝗻𝗴 𝗗𝗠𝗖𝗔,
𝗣𝗹𝗲𝗮𝘀𝗲 𝘀𝗲𝗻𝗱 𝘂𝘀 𝗮𝗻 𝗲𝗺𝗮𝗶𝗹 𝗮𝘁 dmca@enspirers.com


